Data Source¶
FANTASIA requires two types of data:
The input data, provided by the user (protein sequences in FASTA format).
The reference data (lookup table), which contains precomputed embeddings and GO annotations used for nearest-neighbor annotation transfer.
This reference table was generated using the Protein Information System (PIS) [1], an integrated and automated platform that extracts protein data from UniProt, PDB, and GOA, and computes protein embeddings using modern Protein Language Models (PLMs).
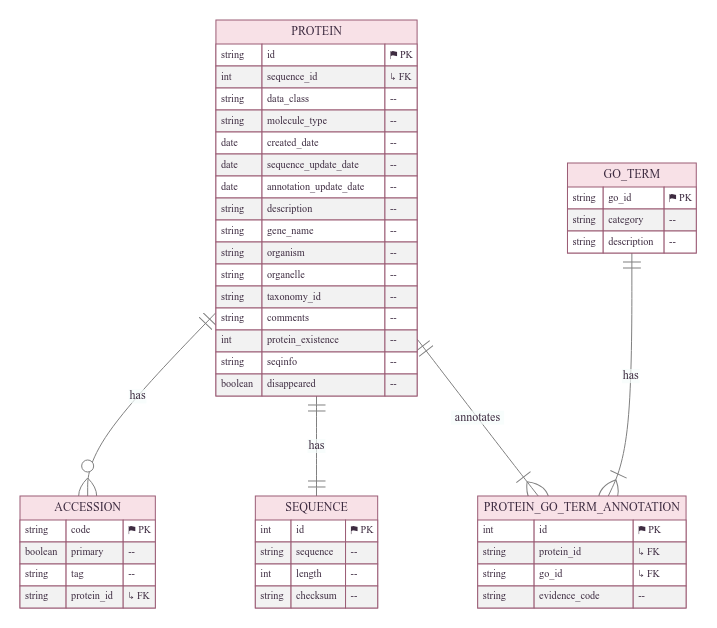
Embeddings from multiple models are computed for each protein sequence.¶
Default Reference Dataset – FANTASIA V3¶
The lookup table used by FANTASIA V3 was generated in late July 2025 using version 2.0.0 of the Protein Information System (PIS).
It consists of a PostgreSQL database backup using the pgvector extension to store protein embeddings.
This reference includes only experimentally supported annotations, extracted directly from UniProt. It is the default and recommended dataset for functional annotation in FANTASIA.
Key improvements over previous versions (GOA2022, GOA2024, GOA2025 APRIL):
Fixed a bug that truncated embeddings to 512 dimensions.
Expanded model coverage from 3 to 5 PLMs, now including Ankh3-Large and ESM3c.
Replaced ESM-1b (8M parameters) with ESM-2 (650M parameters).
Removed computational annotations; includes only GO terms with experimental evidence codes.
Dataset Details¶
Total proteins: 127,546
Total sequences: 124,397
Total embeddings: 621,849
Total GO annotations: 627,932
Included GO evidence codes (experimental only):
EXP – Inferred from Experiment
IDA – Inferred from Direct Assay
IPI – Inferred from Physical Interaction
IMP – Inferred from Mutant Phenotype
IGI – Inferred from Genetic Interaction
IEP – Inferred from Expression Pattern
TAS – Traceable Author Statement
IC – Inferred by Curator
Supported Embedding Models¶
ESM-2 (650M parameters)
ProtT5-XL-UniRef50 (~1.2B parameters)
ProstT5 (~1.2B parameters)
Ankh3-Large (620M parameters)
ESM3c (Cambrian 600M)
Each model provides high-dimensional representations of protein sequences used for functional similarity comparisons.
Missing Proteins¶
A small number of proteins could not be processed on the Finisterrae III (CESGA) supercomputer due to memory limitations on 40 GB A100 GPUs.